Exploring Data Modeling Techniques: (Relational, Dimensional, ...)
This is part of the Data Engineering Roadmap.
2. Data Modeling — data modeling techniques: (Relational, Dimensional, …).
Data modeling techniques refer to various methodologies and approaches used to design and structure data in databases or data warehouses. These techniques aim to represent real-world entities, their relationships, and attributes in a way that facilitates efficient storage, retrieval, and analysis of data. Some common data modeling techniques include:
1. Relational Modeling:
- Relational modeling is based on the principles of the relational database model, as proposed by E.F. Codd.
- It involves organizing data into tables, each representing a specific entity or relationship.
- Entity-Relationship Diagrams (ERDs) are commonly used to visually represent relational schemas.
- Normalization techniques are applied to minimize redundancy and dependency, ensuring data integrity.
- Relational modeling is well-suited for transactional systems and applications with complex data interdependencies.
Let’s consider a simple example to illustrate the relational model.
Suppose we are modeling data for a university. We might have entities such as “Students,” “Courses,” and “Instructors,” each with their own attributes. Here’s how we could represent these entities using tables in a relational database:
- Students Table:
- Attributes: StudentID (Primary Key), Name, Age, Major
+-----------+--------------+-----+------------------+
| StudentID | Name | Age | Major |
+-----------+--------------+-----+------------------+
| 1001 | John Smith | 20 | Computer Science |
| 1002 | Alice Johnson| 22 | Biology |
| 1003 | Emily Davis | 21 | History |
| ... | ... | ... | ... |
+-----------+--------------+-----+------------------+2. Courses Table:
- Attributes: CourseID (Primary Key), Title, InstructorID (Foreign Key).
+----------+----------------------+--------------+
| CourseID | Title | InstructorID |
+----------+----------------------+--------------+
| 2001 | Introduction to CS | 3001 |
| 2002 | Biology 101 | 3002 |
| 2003 | World History | 3003 |
| ... | ... | ... |
+----------+----------------------+--------------+3. Instructors Table:
- Attributes: InstructorID (Primary Key), Name, Department.
+--------------+--------------+-------------------+
| InstructorID | Name | Department |
+--------------+--------------+-------------------+
| 3001 | Dr. Smith | Computer Science |
| 3002 | Prof. Johnson| Biology |
| 3003 | Dr. Davis | History |
| ... | ... | ... |
+--------------+--------------+-------------------+In this example:
- Each table represents a distinct entity (Students, Courses, Instructors).
- The primary key uniquely identifies each record within the table (StudentID, CourseID, InstructorID).
- Foreign keys establish relationships between tables (e.g., the InstructorID in the Courses table references the corresponding InstructorID in the Instructors table).
- Attributes provide additional details about each entity (e.g., Name, Age, Major).
This relational model allows us to query and analyze the data efficiently, while also maintaining data integrity through relationships and constraints.
2. Dimensional Modeling:
- Dimensional modeling is primarily used in data warehousing and business intelligence environments.
- It revolves around creating star or snowflake schemas, consisting of fact and dimension tables.
- Fact tables store quantitative data (facts), while dimension tables provide descriptive context through attributes.
- Hierarchies and granularities within dimensional models enable drill-down analysis and aggregation.
- Dimensional modeling is optimized for analytical querying, reporting, and decision support.
Let’s consider a dimensional model example for a retail business, where we want to analyze sales data:
- Fact Table — Sales:
- This table captures transactional data, such as sales amounts, quantities, and timestamps.
+------------+------------+----------+---------+------------+
| SalesID | DateKey | ProductID| StoreID | SalesAmount|
+------------+------------+----------+---------+------------+
| 1 | 20240101 | 101 | 201 | 100.00 |
| 2 | 20240101 | 102 | 202 | 75.00 |
| 3 | 20240102 | 101 | 203 | 120.00 |
| ... | ... | ... | ... | ... |
+------------+------------+----------+---------+------------+- SalesID: Primary key for the fact table.
- DateKey: Foreign key referencing a Date dimension table.
- ProductID: Foreign key referencing a Product dimension table.
- StoreID: Foreign key referencing a Store dimension table.
- SalesAmount: Quantitative measure of sales.
2. Dimension Table — Date:
- This table contains date-related attributes, such as day, month, year, and fiscal periods.
+--------+------------+-------+------+--------+
| DateKey| Date | Day | Month| Year |
+--------+------------+-------+------+--------+
| 20240101| 2024-01-01| 01 | 01 | 2024 |
| 20240102| 2024-01-02| 02 | 01 | 2024 |
| 20240103| 2024-01-03| 03 | 01 | 2024 |
| ... | ... | ... | ... | ... |
+--------+------------+-------+------+--------+- DateKey: Primary key for the Date dimension.
- Date: Date in YYYY-MM-DD format.
- Day: Day of the month.
- Month: Month of the year.
- Year: Year.
3. Dimension Table — Product:
- This table contains product-related attributes, such as product name, category, and brand.
+----------+------------+---------+--------+
| ProductID| ProductName| Category| Brand |
+----------+------------+---------+--------+
| 101 | Laptop | Electronics| XYZ |
| 102 | Smartphone | Electronics| ABC |
| 103 | T-shirt | Apparel | DEF |
| ... | ... | ... | ... |
+----------+------------+---------+--------+- ProductID: Primary key for the Product dimension.
- ProductName: Name of the product.
- Category: Product category.
- Brand: Product brand.
4. Dimension Table — Store:
- This table contains store-related attributes, such as store name, location, and manager.
+---------+------------+-------------+-------------+
| StoreID | StoreName | Location | Manager |
+---------+------------+-------------+-------------+
| 201 | Store A | New York | John Doe |
| 202 | Store B | Los Angeles | Jane Smith |
| 203 | Store C | Chicago | Mike Johnson|
| ... | ... | ... | ... |
+---------+------------+----------+----------------+- StoreID: Primary key for the Store dimension.
- StoreName: Name of the store.
- Location: Store location.
- Manager: Store manager.
In this dimensional model:
- The fact table (Sales) contains transactional data and foreign keys referencing dimension tables.
- Dimension tables (Date, Product, Store) contain descriptive attributes related to specific dimensions.
- The model facilitates analytical queries and reporting by organizing data into a star schema, allowing for easy navigation and aggregation along different dimensions (e.g., time, product, store).
3. Object-Oriented Modeling:
- Object-oriented modeling extends the concepts of object-oriented programming to data modeling.
- It represents data as objects with properties (attributes) and behaviors (methods), allowing for encapsulation and inheritance.
- Object-oriented databases (OODBs) are designed to store and retrieve objects directly, offering benefits for applications with complex data structures.
Let’s consider an example of object-oriented modeling for a library management system:
Class: Book
Attributes:
- ISBN (String): International Standard Book Number.
- Title (String): Title of the book.
- Author (String): Author(s) of the book.
- Genre (String): Genre or category of the book.
- PublicationYear (Integer): Year the book was published.
- AvailableCopies (Integer): Number of copies available for borrowing.
Methods:
- CheckOut(): Decrements the number of available copies when a book is checked out.
- Return(): Increments the number of available copies when a book is returned.
Class: Member
Attributes:
- MemberID (String): Unique identifier for the library member.
- Name (String): Name of the member.
- Address (String): Address of the member.
- Email (String): Email address of the member.
- Phone (String): Phone number of the member.
Methods:
- BorrowBook(Book book): Allows the member to borrow a book from the library.
- ReturnBook(Book book): Allows the member to return a borrowed book to the library.
Class: Library
Attributes:
- Books (List<Book>): Collection of books available in the library.
- Members (List<Member>): Collection of registered library members.
Methods:
- AddBook(Book book): Adds a new book to the library’s collection.
- RemoveBook(Book book): Removes a book from the library’s collection.
- RegisterMember(Member member): Registers a new member with the library.
- RemoveMember(Member member): Removes a member from the library’s records.
- SearchBookByTitle(String title): Searches for a book by its title.
- SearchBookByAuthor(String author): Searches for books by a specific author.
- SearchBookByGenre(String genre): Searches for books within a specific genre.
In this object-oriented model:
- The Book class represents individual books with attributes such as ISBN, title, author, etc.
- The Member class represents library members with attributes like name, address, etc.
- The Library class acts as a container for books and members, providing methods to manage the library’s inventory and membership.
- Encapsulation is achieved by encapsulating related data and functionality within each class.
- Inheritance and polymorphism could be implemented to extend the functionality of these classes further, such as creating specialized types of books or members.
4. Entity-Attribute-Value (EAV) Modeling:
- EAV modeling is a flexible approach used to represent sparse or dynamic data where the attributes vary significantly between entities.
- It involves storing data in a table with three columns: entity, attribute, and value.
- EAV modeling is commonly used in scenarios such as custom fields in software applications or medical records with varying sets of attributes per patient.
let’s consider an Entity-Attribute-Value (EAV) modeling example for tracking stock information:
In EAV modeling, instead of having fixed columns for every attribute of an entity (such as stocks), we store attribute-value pairs in a flexible structure. This allows for storing diverse and potentially sparse data without requiring schema changes.
Let’s create tables for Stock entities and their attributes:
- Entity Table: Stock
- This table stores the primary information about each stock entity.
+-----------+------------+
| StockID | Name |
+-----------+------------+
| 1 | AAPL |
| 2 | GOOG |
| 3 | MSFT |
| ... | ... |
+-----------+------------+2. Attribute Table: Attribute
- This table stores the attributes associated with stocks.
+-----------+------------+
| AttributeID| Name |
+-----------+------------+
| 1 | Price |
| 2 | MarketCap |
| 3 | P/E Ratio |
| ... | ... |
+-----------+------------+3. Value Table: Value
- This table stores the attribute-value pairs for each stock entity.
+-----------+--------------+------------+-------------+
| StockID | AttributeID | Value | Date |
+-----------+--------------+------------+-------------+
| 1 | 1 | 150.25 | 2024-04-15 |
| 1 | 2 | 2.5T | 2024-04-15 |
| 1 | 3 | 28.6 | 2024-04-15 |
| 2 | 1 | 2805.89 | 2024-04-15 |
| 2 | 2 | 1.9T | 2024-04-15 |
| ... | ... | ... | ... |
+-----------+--------------+------------+-------------+In this example:
- The Stock table contains a list of stocks identified by StockID and Name.
- The Attribute table contains a list of attributes (e.g., Price, MarketCap, P/E Ratio) identified by AttributeID and Name.
- The Value table stores the attribute-value pairs for each stock entity, with columns for StockID, AttributeID, Value, and Date.
- Each row in the Value table represents an attribute-value pair for a specific stock entity on a given date.
With this EAV model, we can easily add new attributes without altering the schema, allowing for flexibility in tracking diverse stock-related information. However, querying data from an EAV model can be more complex compared to traditional relational models due to the need for dynamic pivoting and handling sparse data.
5. Graph Modeling:
- Graph modeling represents data as nodes (entities) and edges (relationships) in a graph structure.
- It is particularly useful for modeling complex relationships and network data, such as social networks, recommendation systems, and network analysis.
These are just a few examples of data modeling techniques, each suited to different use cases and requirements. Data engineers and database architects often select and combine these techniques based on the specific needs of the application, performance considerations, and scalability requirements.
Types of Data Models
- Conceptual Data Model
- This provides a high-level overview of each data entity, focusing on their attributes and relationships, without delving into technical intricacies.
- It showcases all pertinent data entities within the business context, along with their defining attributes and the interconnections, or relationships, among them.
- By offering a clear and accessible representation, it facilitates effective communication among stakeholders, thereby minimizing potential communication barriers.
2. Logical Data Model
- This describes all the bits of personal information, including what they are and how they’re connected, so each piece of data makes sense for the business.
- It explains relationships in more detail, like which pieces of information are most important, how they connect to each other, and how some are more important than others.
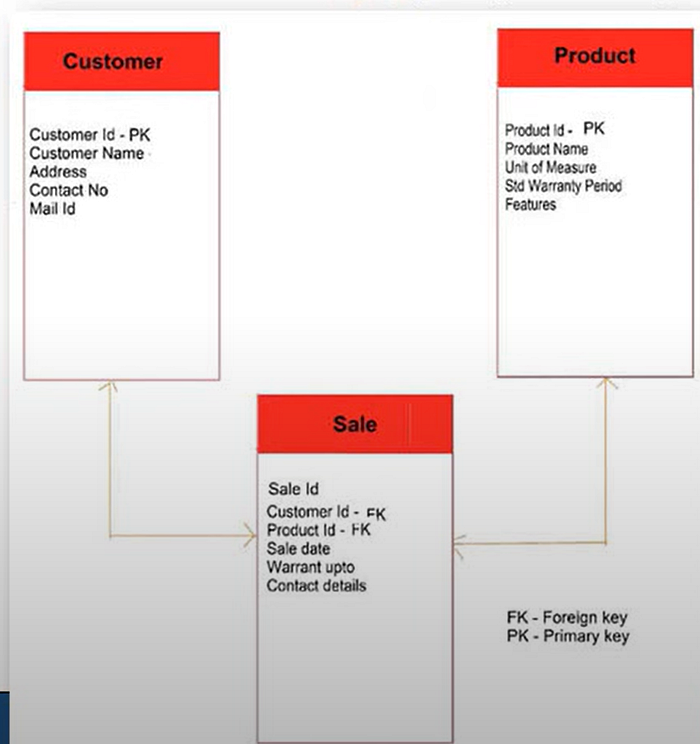
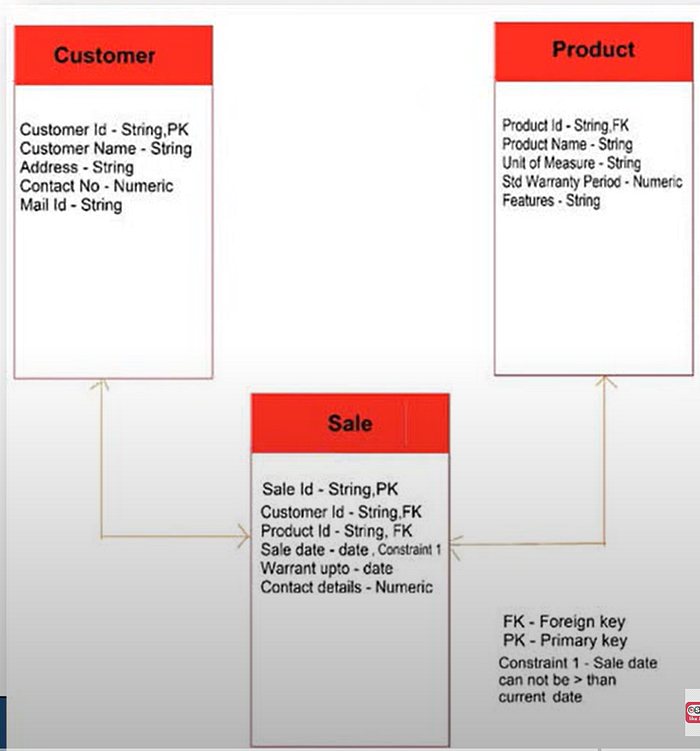
3. Physical Data Model
- The physical data model encompasses the structural arrangement of the database, encompassing all constituent elements.
- It provides a detailed technical perspective, delineating aspects such as table names, column names, data types, constraints, indexes, primary keys, triggers, stored procedures, and other pertinent attributes.
- Development of the physical data model typically involves the utilization of database management systems such as SQL, ORACLE, among others.
Why Data Modeling?
- It serves as a foundation for constructing information systems and databases.
- Streamlines the retrieval of business data, enhancing accessibility.
- Empowers management in making informed decisions.
- Enhances operational efficiency within the business.
- Ensures all stakeholders possess a lucid comprehension of the forthcoming data storage.
- Establishes the fundamental rules and regulations governing each entity within the system.
Data Modeling Tools
1. MySQL Workbench
2. ER/Studio
3. erwin Data Modeler
4. SQuirreL SQL Client
5. Amundsen
6. Postico
7. Navicat
8. Datagrip
Conclusion
In the article we have essentially discussed, what are the ways in which we can store our data in a database. This is quite critical and largely depends on the type of data and its usecase. What factor is it that you want to optimize going forward. Having said that, the decision should be takes after a rigorous consideration of all the future needs and demands from the database. In the end, practice makes you skilled and experiences help you in taking better decisions. Happy Learning !!!