Database Schema — Best Practices
What is Schema in the Database Management System?
A database schema embodies the blueprint of a database, encompassing its entire structure. To illustrate the points with examples, I’ll be taking some financial data and building some schemas. You can try out on your own to disign your database schema. This blueprint comprises three fundamental facets:
1. Physical Schema: This aspect delineates how data is physically organized within the database, focusing on the storage details like blocks or bytes.
2. Logical Schema: Operating at a higher level of abstraction, the logical schema defines the database design in a way that programmers and administrators comprehend. It focuses on data types, structures, and their relationships while concealing intricate internal implementation specifics.
3. View Schema: This layer represents the database’s interface for end-users. It facilitates user interaction through interfaces like GUIs, shielding users from underlying data storage intricacies.
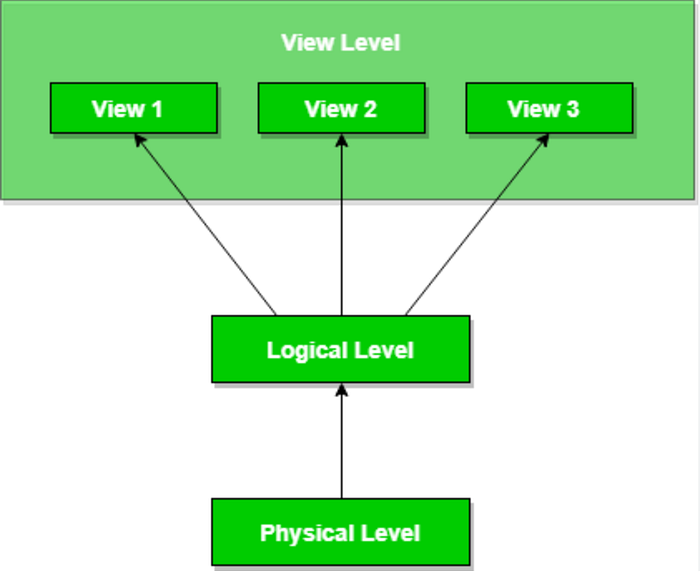
Consider a scenario of storing student information. At the physical level, records are stored as raw data, concealed within storage blocks. At the logical level, these records are shaped into fields and attributes with defined data types and logical relationships. Programmers operate here, being aware of database functionality. Finally, at the view level, users interact with an intuitive interface without knowledge of data storage specifics.
In a database’s architectural model, these schema types conform to three levels of abstraction:
1. External Schemas (View Level): Corresponding to various user views, these schemas represent different external data perspectives.
2. Conceptual Schema (Logical Schema): This schema amalgamates all entities, attributes, relationships, and integrity constraints within the database.
3. Internal Schema (Physical Schema): Representing the lowest abstraction level, this schema furnishes a detailed portrayal of the database’s internal structure, including data classifications, storage methods, and storage structures.
Noteworthy is the DBMS’s role in managing the mapping between these schema types. It ensures consistency by validating that each external schema derives from the conceptual schema, facilitating mapping between external and internal schemas.
Furthermore, the DBMS conducts schema consistency checks, ensuring conformity in entity names, attribute order, data types, etc. It leverages the external-to-conceptual mapping, enabling seamless correlation between user-observable schema elements and the underlying conceptual schema.
Creating Database Schema
To establish a schema within a database, the command “CREATE SCHEMA” serves as the universal directive, albeit with varying implications across different database systems. Let’s delve into the nuances of schema creation in distinct database environments:
1. MySQL: Within MySQL, the “CREATE SCHEMA” command is employed to generate a database. This is due to the similarity between “CREATE SCHEMA” and “CREATE DATABASE” in MySQL.
2. SQL Server: In SQL Server, the “CREATE SCHEMA” statement is utilized explicitly to instantiate a fresh schema within the database.
3. Oracle Database: The process diverges in Oracle Database, where the “CREATE USER” statement assumes the role of schema creation. Oracle automatically generates a schema for each database user. Notably, “CREATE SCHEMA” in Oracle does not engender a schema; rather, it populates the schema with tables and views. Additionally, it streamlines access to these objects, obviating the necessity for multiple SQL statements during diverse transactions.
Database Schema Designs
Creating a database involves employing diverse schema designs, each tailored to specific needs. Optimal schema design is pivotal as inefficient designs pose challenges in management, consuming excessive memory and resources.
The selection of a schema design predominantly hinges upon the unique demands of the application. Let’s explore various efficient schema designs suited for developing applications:
- Flat Model: The flat model schema resembles a 2-dimensional grid where each column holds identical types of data while the elements within rows share relationships. Think of it as akin to a table or a spreadsheet structure. It’s well-suited for smaller applications that lack intricate or complicated data structures.

CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Department VARCHAR(50),
Salary DECIMAL(10, 2)
);
CREATE TABLE OHLCV_Data (
Date DATE,
Open FLOAT,
High FLOAT,
Low FLOAT,
Close FLOAT,
Volume INT
);
2. Hierarchical Model: Organized in a tree-like structure with parent-child relationships, this model suits scenarios where data follows a hierarchical order.
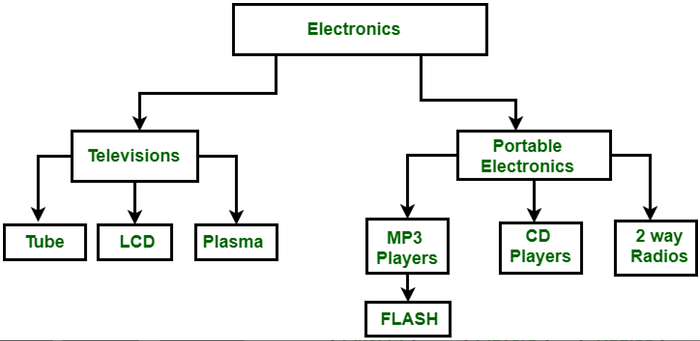
The Hierarchical Database Model organizes data using a parent-child relationship, resembling a tree-like structure. In this model, each record has multiple children and one parent, making it suitable for illustrating one-to-many relationships, much like organizational charts. However, its simplicity might limit its adaptability in handling complex relationships.
For convinience, we can take financial data to illustrate the process.
- Parent Table: Contains general information (e.g., Date, Ticker symbol).
- Child Table: Contains OHLCV data linked to the parent table by a unique identifier (e.g., Date).
-- Create parent table
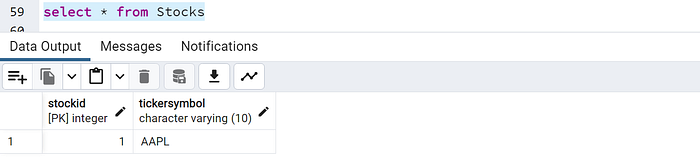
CREATE TABLE Stocks (
StockID SERIAL PRIMARY KEY,
TickerSymbol VARCHAR(10) NOT NULL
);
-- Create child table
CREATE TABLE OHLCV_Data (
DataID SERIAL PRIMARY KEY,
StockID INT REFERENCES Stocks(StockID),
Date DATE,
Open FLOAT,
High FLOAT,
Low FLOAT,
Close FLOAT,
Volume INT
);
-- Insert data into the parent table (AAPL)
INSERT INTO Stocks (TickerSymbol) VALUES ('AAPL');
-- Insert data into the child table (OHLCV data for AAPL)
INSERT INTO OHLCV_Data (StockID, Date, Open, High, Low, Close, Volume)
VALUES (1, '2023-11-29', 150.00, 152.50, 149.80, 151.30, 500000),
(1, '2023-11-28', 148.00, 151.20, 147.50, 150.80, 600000);
-- Query to display OHLCV data for AAPL stock
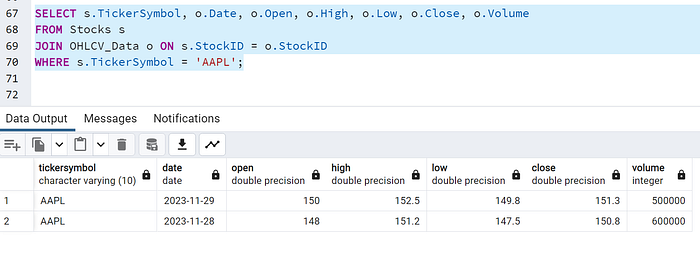
SELECT s.TickerSymbol, o.Date, o.Open, o.High, o.Low, o.Close, o.Volume
FROM Stocks s
JOIN OHLCV_Data o ON s.StockID = o.StockID
WHERE s.TickerSymbol = 'AAPL';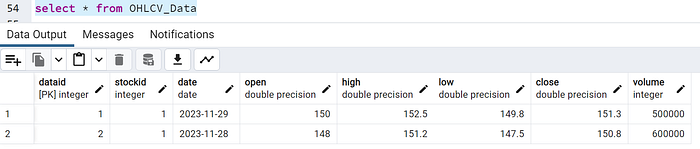
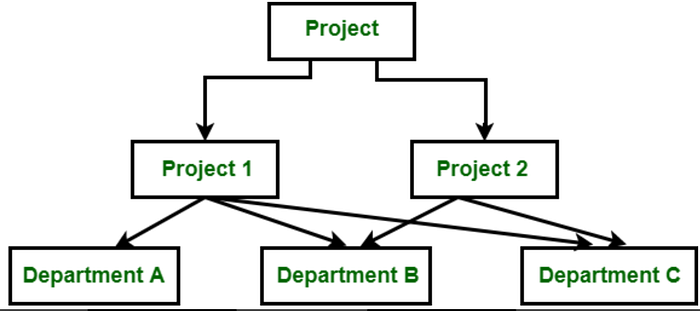
3. Network Model: The network model and the hierarchical model bear resemblances, yet a crucial distinction lies in their treatment of data relationships. While both models handle connections between data entities, the network model accommodates many-to-many relationships, whereas hierarchical models primarily support one-to-many relationships.
- Main Table: Contains general information (e.g., Stock ID, Date).
- Linked Table: Stores OHLCV data linked to other records by unique identifiers.
-- Create main table
CREATE TABLE MainTable (
MainID SERIAL PRIMARY KEY,
StockID INT REFERENCES Stocks(StockID),
Date DATE
);
-- Create linked table
CREATE TABLE LinkedTable (
LinkedID SERIAL PRIMARY KEY,
MainID INT REFERENCES MainTable(MainID),
Open FLOAT,
High FLOAT,
Low FLOAT,
Close FLOAT,
Volume INT
);
-- Insert data into the main table (AAPL)
INSERT INTO MainTable (StockID, Date)
VALUES (1, '2023-11-29'),
(1, '2023-11-28');
-- Insert data into the linked table (OHLCV data for AAPL)
INSERT INTO LinkedTable (MainID, Open, High, Low, Close, Volume)
VALUES (1, 150.00, 152.50, 149.80, 151.30, 500000),
(1, 148.00, 151.20, 147.50, 150.80, 600000);
-- Query to display OHLCV data for AAPL stock
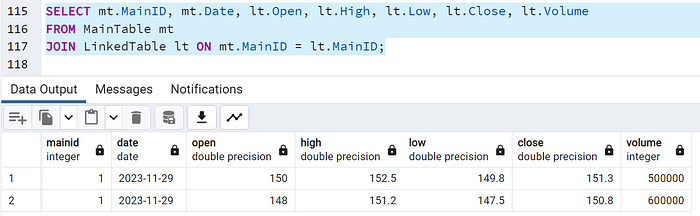
SELECT mt.MainID, mt.Date, lt.Open, lt.High, lt.Low, lt.Close, lt.Volume
FROM MainTable mt
JOIN LinkedTable lt ON mt.MainID = lt.MainID;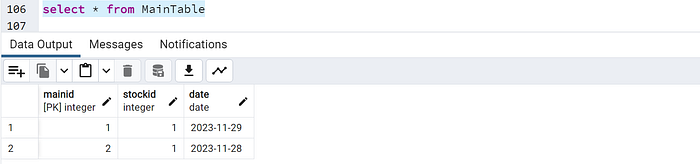

4. Relational Model: The relational model serves as the foundation for relational databases, organizing data into tables or relations. In this model, relationships exist between tables, allowing data retrieval and manipulation through structured queries. This schema is notably advantageous for object-oriented programming due to its structured nature.
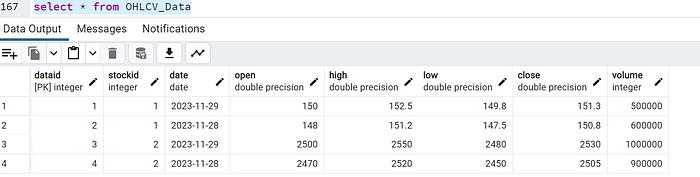
-- Create table for storing stocks information
CREATE TABLE Stocks (
StockID SERIAL PRIMARY KEY,
TickerSymbol VARCHAR(10) NOT NULL
);
-- Create table for OHLCV data related to stocks
CREATE TABLE OHLCV_Data (
DataID SERIAL PRIMARY KEY,
StockID INT REFERENCES Stocks(StockID),
Date DATE,
Open FLOAT,
High FLOAT,
Low FLOAT,
Close FLOAT,
Volume INT
);
-- Insert data for AAPL (Apple Inc.) into Stocks table
INSERT INTO Stocks (TickerSymbol) VALUES ('AAPL');
-- Insert OHLCV data for AAPL into OHLCV_Data table
INSERT INTO OHLCV_Data (StockID, Date, Open, High, Low, Close, Volume)
VALUES (1, '2023-11-29', 150.00, 152.50, 149.80, 151.30, 500000),
(1, '2023-11-28', 148.00, 151.20, 147.50, 150.80, 600000);
-- Insert data for RELIANCE into Stocks table
INSERT INTO Stocks (TickerSymbol) VALUES ('RELIANCE');
-- Insert OHLCV data for RELIANCE into OHLCV_Data table
INSERT INTO OHLCV_Data (StockID, Date, Open, High, Low, Close, Volume)
VALUES (2, '2023-11-29', 2500.00, 2550.00, 2480.00, 2530.00, 1000000),
(2, '2023-11-28', 2470.00, 2520.00, 2450.00, 2505.00, 900000);
-- Query to display OHLCV data for AAPL and RELIANCE stocks
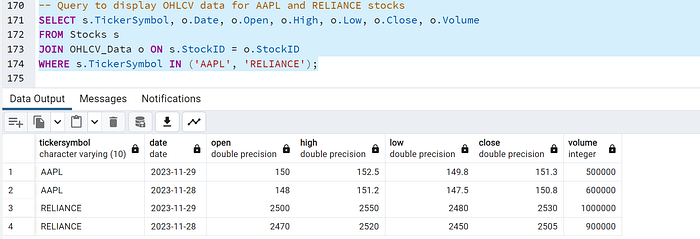
SELECT s.TickerSymbol, o.Date, o.Open, o.High, o.Low, o.Close, o.Volume
FROM Stocks s
JOIN OHLCV_Data o ON s.StockID = o.StockID
WHERE s.TickerSymbol IN ('AAPL', 'RELIANCE');
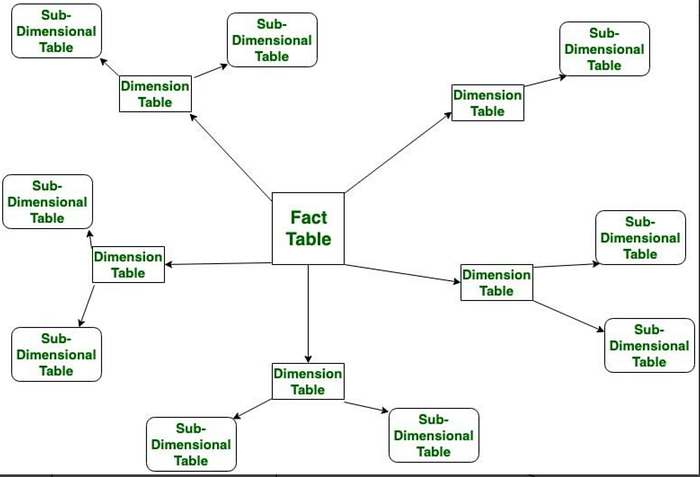
5. Star Schema: The star schema proves beneficial when managing and analyzing extensive datasets. This schema model revolves around a central fact table and multiple associated dimension tables, resembling a star’s structure. The fact table contains quantitative data driving core business operations, while the dimension tables hold contextual details regarding various aspects like products, time, individuals, etc. Essentially, dimension tables provide descriptions or attributes related to the entries in the fact table. Implementing a star schema offers an organized structure to handle data within Relational Database Management Systems (RDBMS).
-- Create fact table for OHLCV data
CREATE TABLE Fact_OHLCV (
FactID SERIAL PRIMARY KEY,
StockID INT,
Date DATE,
Open FLOAT,
High FLOAT,
Low FLOAT,
Close FLOAT,
Volume INT,
CONSTRAINT fk_stock FOREIGN KEY (StockID) REFERENCES Stocks(StockID)
);
-- Create dimension table for Stocks
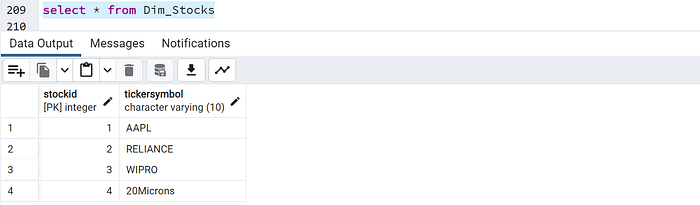
CREATE TABLE Dim_Stocks (
StockID SERIAL PRIMARY KEY,
TickerSymbol VARCHAR(10) NOT NULL
);
-- Create dimension table for Time
CREATE TABLE Dim_Time (
TimeID SERIAL PRIMARY KEY,
Date DATE
-- Add more time-related attributes as needed
);
-- Insert data into Dim_Stocks table for various stocks
INSERT INTO Dim_Stocks (TickerSymbol)
VALUES ('AAPL'), ('RELIANCE'), ('WIPRO'), ('20Microns');
-- Insert data into Dim_Time table for dates
INSERT INTO Dim_Time (Date)
VALUES ('2023-11-29'), ('2023-11-28');
-- Insert OHLCV data into Fact_OHLCV table for stocks
INSERT INTO Fact_OHLCV (StockID, Date, Open, High, Low, Close, Volume)
VALUES (1, '2023-11-29', 150.00, 152.50, 149.80, 151.30, 500000),
(2, '2023-11-29', 2500.00, 2550.00, 2480.00, 2530.00, 1000000);
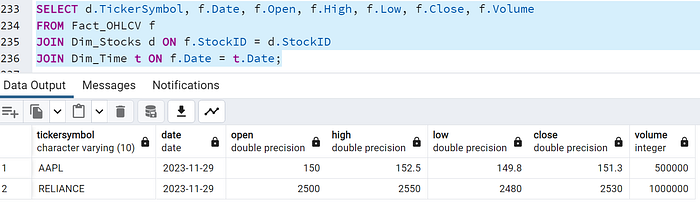
SELECT d.TickerSymbol, f.Date, f.Open, f.High, f.Low, f.Close, f.Volume
FROM Fact_OHLCV f
JOIN Dim_Stocks d ON f.StockID = d.StockID
JOIN Dim_Time t ON f.Date = t.Date;
6. Snowflake Schema: The snowflake schema, akin to the star schema, features a central fact table surrounded by multiple dimension tables. However, the significant divergence lies in the snowflake schema’s dimension tables, which undergo further normalization into multiple related tables. This normalization process involves breaking down dimension tables into additional related tables, creating a more complex yet organized structure. The snowflake schema serves as an effective model for analyzing substantial volumes of data due to its structured design.
-- Create fact table for OHLCV data
CREATE TABLE Fact_OHLCV (
FactID SERIAL PRIMARY KEY,
StockID INT REFERENCES Dim_Stocks(StockID),
Date DATE REFERENCES Dim_Dates(Date),
Open FLOAT,
High FLOAT,
Low FLOAT,
Close FLOAT,
Volume INT
);
-- Create dimension table for Stocks
CREATE TABLE Dim_Stocks (
StockID SERIAL PRIMARY KEY,
TickerSymbol VARCHAR(10) NOT NULL
);
select * from Dim_Stocks
-- Create dimension table for Dates
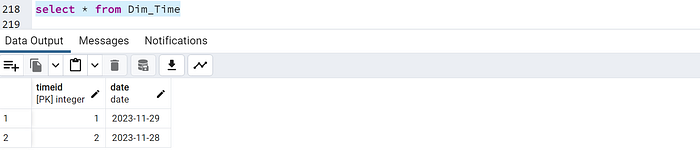
CREATE TABLE Dim_Dates (
Date DATE PRIMARY KEY
-- Add more date-related attributes as needed
);
select * from Dim_Dates
-- Insert data into Dim_Stocks table for various stocks
INSERT INTO Dim_Stocks (TickerSymbol)
VALUES ('AAPL'), ('RELIANCE'), ('WIPRO'), ('20Microns');
-- Insert data into Dim_Dates table for dates
INSERT INTO Dim_Dates (Date)
VALUES ('2023-11-29'), ('2023-11-28');
-- Insert OHLCV data into Fact_OHLCV table for stocks and dates
INSERT INTO Fact_OHLCV (StockID, Date, Open, High, Low, Close, Volume)
VALUES (1, '2023-11-29', 150.00, 152.50, 149.80, 151.30, 500000),
(2, '2023-11-29', 2500.00, 2550.00, 2480.00, 2530.00, 1000000);
SELECT ds.TickerSymbol, dd.Date, f.Open, f.High, f.Low, f.Close, f.Volume
FROM Fact_OHLCV f
JOIN Dim_Stocks ds ON f.StockID = ds.StockID
JOIN Dim_Dates dd ON f.Date = dd.Date;
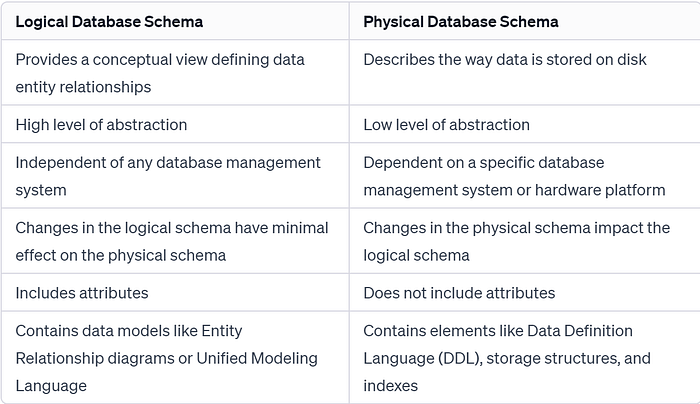
Difference between Logical and Physical Database Schema
Benefits of Database Schema
1. Enforcing Data Consistency: The database schema plays a pivotal role in upholding data consistency by preventing duplications and ensuring uniformity across datasets.
2. Scalability Support: A well-crafted database schema facilitates the seamless addition of new tables within the database. It also efficiently manages the handling of burgeoning data volumes within expanding tables.
3. Enhanced Performance: By organizing data in a structured manner, the database schema contributes to expedited data retrieval processes. This optimization significantly reduces operation time when interacting with database tables.
4. Simplified Maintenance: Database schema implementation aids in streamlining overall database maintenance without causing disruptions to other database components. This ensures smooth and hassle-free database management.
5. Data Security Measures: Implementing a robust database schema fortifies data security by providing a framework to store sensitive information securely. It grants access only to authorized personnel, bolstering the overall security posture of the database.
Database Instance
The database schema is established before the database creation process. Once the database becomes active, altering the schema poses considerable challenges as it embodies the foundational framework of the database structure. The database instance, distinct from storing actual data, does not retain information concerning the stored data within the database. Consequently, a database instance reflects the precise snapshot of data and details currently existing within the database at a particular moment in time.
-- Create OHLCV table
CREATE TABLE ohlcv (
id SERIAL PRIMARY KEY,
stock_symbol VARCHAR(10),
date DATE,
open_price NUMERIC(10, 2),
high_price NUMERIC(10, 2),
low_price NUMERIC(10, 2),
close_price NUMERIC(10, 2),
volume INT
);
-- Insert sample data into the OHLCV table
INSERT INTO ohlcv (stock_symbol, date, open_price, high_price, low_price, close_price, volume)
VALUES
('AAPL', '2023-11-29', 150.00, 152.50, 149.80, 151.30, 500000),
('AAPL', '2023-11-30', 152.00, 153.20, 150.50, 151.80, 600000),
('GOOGL', '2023-11-29', 2800.00, 2820.50, 2780.80, 2810.30, 300000),
('GOOGL', '2023-11-30', 2820.00, 2835.20, 2800.50, 2825.80, 400000);
SELECT *
FROM ohlcv
WHERE date <= '2023-11-30 12:00:00'
ORDER BY date DESC
LIMIT 1;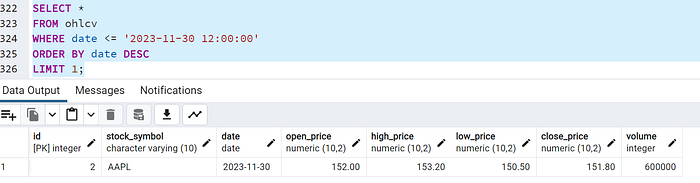
Conclusion
- The configuration or arrangement defining how data is organized within a database is known as the Schema, outlining logical constraints such as tables and keys, among other elements.
- The Three Schema Architecture was devised to restrict direct user access to the database, maintaining a separation between the user interface, logical schema, and physical storage schema.
- Given that data stored in the database undergoes continuous modifications, an Instance embodies a snapshot or representation of the data within the database at a particular point in time.
Hope you enjoyed going through the article. The DB design is a critical step in any major backend system and has to be done carefully. Happy Learning!!! Follow for more such articles.